

Photo by ThisIsEngineering from Pexels
Modern marketing platforms do not run on buzzwords alone. Behind every click, keyword, or backlink report sits a complex web of crawling bots, indexing engines, and data pipelines. Many marketers and product teams rarely think about this foundation. Yet the strength of this unseen system decides how reliable and actionable marketing insights feel.
Today, we’ll look into how large-scale web crawling works in practice, what makes it so tough to get right, and how companies like Ahrefs build deep technical infrastructure to keep marketers ahead.
Web Crawling at Scale
Every keyword or backlink update relies on crawlers that run nonstop. Many think crawling means sending bots to grab some text. That works at a small scale, but real-world crawling demands far more.
At scale, crawlers face millions of shifting targets. Sites change daily. New pages appear while old ones vanish. Some sites block bots completely. Others show different content by device. A reliable crawler must handle billions of pages, follow robots.txt, avoid overloading sites, and process dynamic JavaScript content.
Behind the scenes, distributed systems keep the load balanced worldwide. Smart scheduling spots what needs fresh checks and what stays stable. Storage adds another layer of complexity. Raw HTML needs parsing, deduplication, and spam filtering. Redirects need fixing. Without tight indexing, outdated or low-value data can slip through and mislead marketers.
Ahrefs’ Approach
Enterprise marketing software like Ahrefs runs one of the world’s largest independent web crawlers. No third-party feeds fill the gaps. Everything comes from their hardware and software. Over 15 years of data show how the web shifts every day.
Owning the entire crawling stack brings speed and control. Marketers using Ahrefs do not wonder if data got delayed by an upstream provider. The same in-house supercomputer that powers the crawl also runs AI models built to make sense of massive link graphs.
This independence means that the AI marketing platform keeps a near-real-time map of what connects to what. Their systems handle trillions of links, billions of pages, and detect new sites daily. When marketers dig into site audits or keyword research, they see information collected and processed by a pipeline designed from scratch.
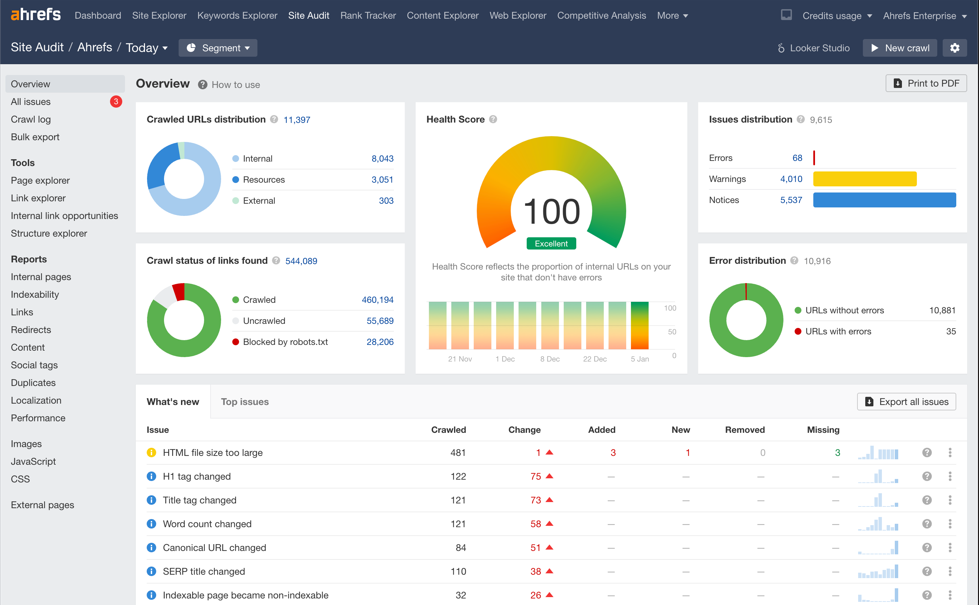
Image: Screenshot of Ahrefs Site Audit dashboard | source: ahrefs.com
This approach costs more time and effort but pays off when search engines shift algorithms, new platforms emerge, or the market demands better insight. Product teams benefit too. New tools ship faster when you do not wait for third parties to adjust their data.
Python and Platform Architecture
No single language holds all the answers for this level of crawling. Python stays popular for prototyping crawlers, orchestrating pipelines, and testing new ranking models. Many teams love its huge library ecosystem and friendly syntax.
Python handles orchestration well. Distributed crawlers coordinate tasks using frameworks like Celery or Airflow. Message brokers like Kafka keep data moving smoothly across regions. When performance needs more speed, heavy lifting moves to compiled languages like Rust or C++.
Storing and analyzing petabytes of crawl data means intelligent indexing. Deduplication, canonical URLs, spam detection, and freshness checks need constant updates. Python scripts help engineers test new filters and models quickly.
Rendering dynamic pages creates another challenge. Many sites rely on JavaScript to serve content. Headless browsers like Puppeteer handle this task, but cost more in resources. Python-based orchestration tools help manage when to render and when to skip.
When it comes to APIs, Python stays handy for stitching together user-facing tools. Marketers expect instant site audits, link reports, and ranking graphs. Fast backends translate massive crawl data into clear insights.
Why the Technical Side Matters
Product teams gain more than performance bragging rights. Having an AI marketing software with a scalable crawler means control over data freshness and quality. Many marketing tools rely on patchwork data from multiple sources. That might work in calm periods, but it leaves teams guessing when search trends shift.
A single missed crawl cycle can lead to outdated rankings. Broken redirects or spammy links might stay hidden. Marketing decisions based on stale data cost money and time. Teams that build and maintain their own crawling and indexing pipelines see these problems before they become user complaints.
Ahrefs stands out because it ties every user feature back to its crawl data. Their AI models run on that same foundation. Whether a marketer needs to analyze competitors, find link-building opportunities, or monitor brand visibility, they get insights powered by data that the company controls end-to-end.
Final Thoughts
A strong digital marketing platform starts with a strong infrastructure. Crawlers, pipelines, and smart architecture decide how reliable and fresh insights feel. Owning these systems takes years of technical investment, but keeps marketers in sync with the real web.
For product and engineering teams, these systems do not feel like back-office chores. They shape every feature you deliver. Better crawling means clearer insights, faster updates, and fewer headaches when trends shift.
Teams like Ahrefs prove that good marketing analytics software grows from the ground up. It starts with the same source as the web itself: data that stays real, current, and fit to support practical, results-driven work.